Tao, Yuchao, et al. "Benchmarking differentially private synthetic data generation algorithms"
The Third AAAI Workshop on Privacy-Preserving Artificial Intelligence (PPAI-22)
This work presents a systematic benchmark of differentially private synthetic data generation algorithms that can generate tabular data. Utility of the synthetic data is evaluated by measuring whether the synthetic data preserve the distribution of individual and pairs of attributes, pairwise correlation as well as on the accuracy of an ML classification model. In a comprehensive empirical evaluation we identify the top performing algorithms and those that consistently fail to beat baseline approaches.
https://arxiv.org/abs/2112.09238
Benchmarking Differentially Private Synthetic Data Generation Algorithms
This work presents a systematic benchmark of differentially private synthetic data generation algorithms that can generate tabular data. Utility of the synthetic data is evaluated by measuring whether the synthetic data preserve the distribution of individ
arxiv.org
https://aaai-ppai22.github.io/#accepted_papers
Third AAAI Workshop on Privacy-Preserving Artificial Intelligence
Aleksandra Korolova University of Southern California korolova@usc.edu
aaai-ppai22.github.io
Synthetic Data (재현 데이터)

실제 데이터와 통계적 특성이 유사하여 실제 데이터를 분석한 결과와 유사한 결과를 얻을 수 있도록 인공적으로 재현하여 생성한 가상 데이터이다.
재현 데이터(synthetic data)는 실제 데이터의 통계적 특성을 파악하여 모델을 만들고, 그 해당 모델에서 생성된 가상 데이터다. 개인정보보호 등을 이유로 실제 데이터에 접근하기 어려운 경우나 학습에 사용될 실제 데이터가 현저히 적은 경우에 사용한다.
재현 데이터는 실제 데이터와 달리 법적인 제약이 적고, 여러 버전으로 많은 양의 데이터를 만들어낼 수 있어 다양한 분석이 가능하다. 초기에는 통곗값을 이용하여 결측 값(missing value; 빠진 데이터)을 대체하는 데 사용하였지만, 점차 기계학습(ML: Machine Learning)과 심층 기계학습(deep learning)을 적용한 데이터 재현으로 발전하였다.
재현 데이터는 텍스트 데이터뿐 아니라 이미지 데이터 재현도 가능한데 생성적 대립 신경망(GAN: Generative Adversarial Network)을 이용하여 의료 분야 재현 데이터를 생성하게 되면, 의료 데이터 사용에 가장 큰 걸림돌인 개인/민감 정보 식별 문제를 해소할 수 있다.
다만, 엄밀한 의미에서 재현 데이터는 실제 데이터가 아니기 때문에 연구 진실성에 대한 논쟁의 소지가 있을 수 있다. 예를 들어, 의료 분야 재현 데이터를 이용하였을 경우 이는 가짜 데이터이기 때문에 연구 진실성을 확보하는 데 한계가 있다. 또 데이터 결과를 의료 행위의 임상적 근거로 사용하는 만큼 잘못된 의료 정보 활용에 따른 문제 발생 가능성이 있다.
Differential Privacy (차분 프라이버시)
차분 프라이버시는 통계 데이터베이스 상에서 수행되는 질의 결과에 의한 개인정보 추론을 방지하기 위한 수학적 모델로써 2006년 Dwork에 의해 처음 소개된 이후로 통계 데이터에 대한 프라이버 보호의 표준으로 자리잡고 있다. 차분 프라이버시는 데이터의 삽입/삭제 또는 변형에 의한 질의 결과의 변화량을 일정 수준 이하로 유지함으로써 정보 노출을 제한하는 개념이다. 이를 구현하기 위해 메커니즘 상의 연구(라플라스 메커니즘, 익스퍼넨셜 메커니즘)와 다양한 데이터 분석 환경(히스토그램, 회귀 분석, 의사 결정 트리, 연관 관계 추론, 클러스터링, 딥러닝 등)에 차분 프라이버시를 적용하는 연구들이 수행되어 왔다.
본 연구에서는 표 형태의 데이터를 생성할 수 있는 차분 개인 합성 데이터 생성 알고리즘의 체계적인 벤치마크를 제시한다.
합성 데이터의 유용성은 합성 데이터가 개별 및 속성 쌍의 분포, 쌍별 상관 관계 및 ML 분류 모델의 정확도를 유지하는지 여부를 측정하여 평가된다.
여기서는 크게 3가지의 알고리즘으로 나누었는데,
먼저, GAN 기반 방법은 주로 그레디언트 계산에 노이즈를 추가하여 생성적 적대 네트워크(GAN)를 학습한다.
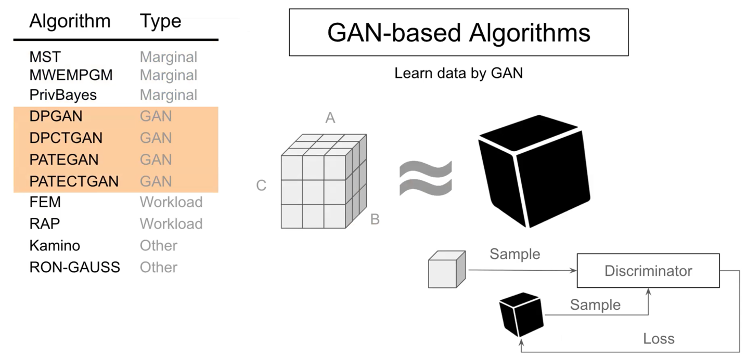
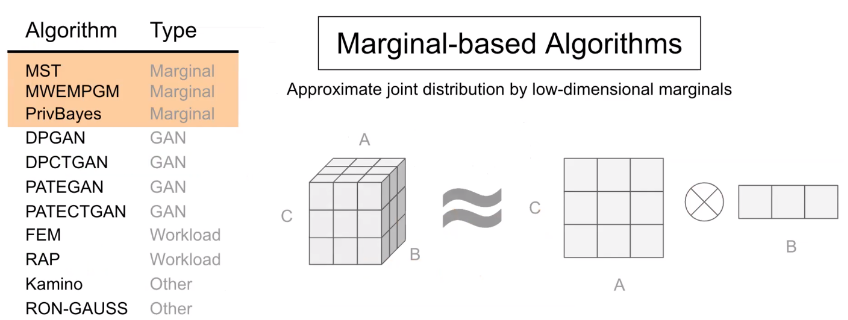
Marginal-based 방법론은 낮은 순위의 Marginals 의 부분 집합을 측정하고, 이를 사용하여 그래픽 모델에 적용한다.
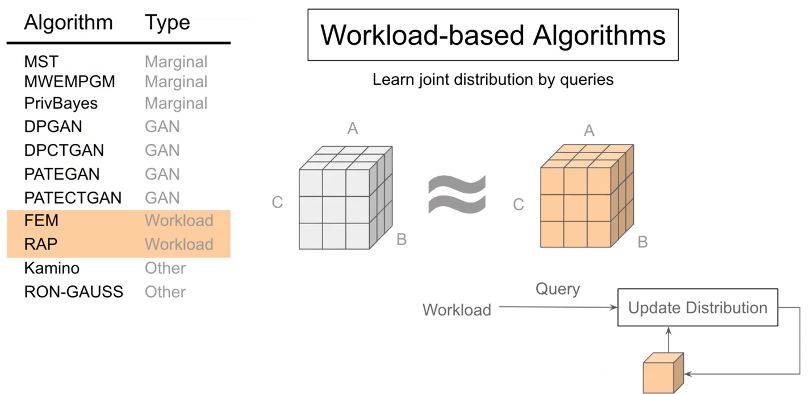
Workload-based (워크로드 기반) 알고리즘은 워크로드 쿼리의 근사 오류를 줄이기 위해 모델을 반복적으로 개선한다.
그리고 벤치마크 연구를 위한 메커니즘으로 5가지 기준을 고려하였는데,
#1 End-to-End DP
- 테이블 형식의 데이터 셋을 동일한 스키마의 합성 데이터로 입력하고 생성한다.
#2 Tabular Data
- 숫자 또는 범주 열을 가질 수 있는 표 형식의 데이터를 지원한다.
#3 Publication Venue
- 좋은 학회나 저널에 잘 알려진 방법론을 선정한다.
#4 Publicly Available Source Code
- 소스 코드가 공개되어 대중적으로 접근 가능한 방법론이여야 한다.
#5 No Public Data
- 공개 데이터가 필요하지 않아야 한다.
그리고 여기서 사용된 데이터셋은 일곱개의 서로 다른 특성을 지닌 데이터셋을 사용하였다.

그리고 각 알고리즘에 의해 생성된 합성 데이터의 적합도를 측정하기 위해 총 4가지의 메트릭 그룹을 고려하였는데, 각 그룹에는 유사한 목표를 가졌지만 서로 다른 지표로 두개 이상 포함시켰다. 이러한 지표는 SDGym 에서 영감을 받았다.
#1 개별 속성 분포 유사성 (Individual Attribute Distribution Similarity, Ind)
이 메트릭 그룹은 합성 데이터와 원본 데이터 간의 단방향 Marginals의 유사성을 측정한다. 총 변동 거리(Total Variation Distance, TVD)를 사용하여 두 개의 1차원 분포 사이의 거리를 측정하고 1-TVD를 점수로 사용한다. 모든 단방향 Marginal에 대한 평균 점수를 최종 점수로 측정한다.
#2 쌍별 속성 분포 유사성 (Pair)
개별 분포 유사성과 유사하게 이 메트릭 그룹은 각 양방향 Marginal에 대한 TVD를 측정하고 모든 특성 쌍에서 평균을 구한다.
#3 쌍별 상관 유사성 (Corr)
편향 보정과 함께 Cramer’s V를 사용하여 두 속성 간의 상관 관계를 측정하고, 이를 4가지 수준으로 구분 짓는다.
#4 분류 정확도 (F1)
합성 데이터를 사용하여 XGBoost 분류기에 학습시켜 이를 이용하여 원본 데이터에 대한 예측을 진행한다.
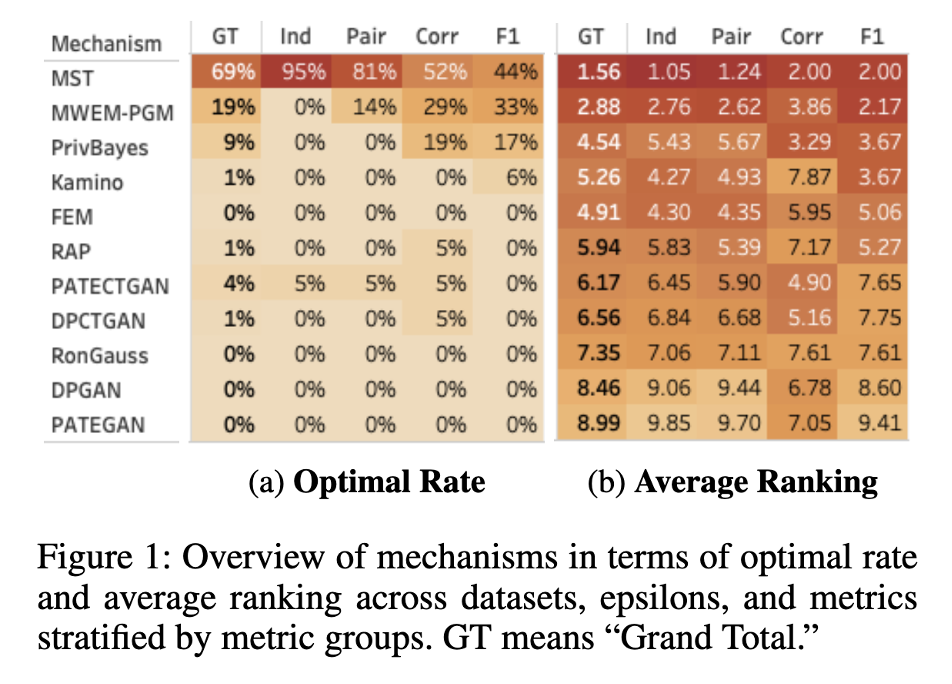
그림 2에서 볼 수 있듯 많은 매커니즘들에서 개별 속성의 분포를 정확히 보존하지 못하는 것을 볼 수 있다.
그리고 아래 그림 3에서는 알고리즘들이 속성 분포를 얼마나 잘 유지하는지에 대한 것을 알기 위해, 몇가지 대표적인 예시를 표현했다.
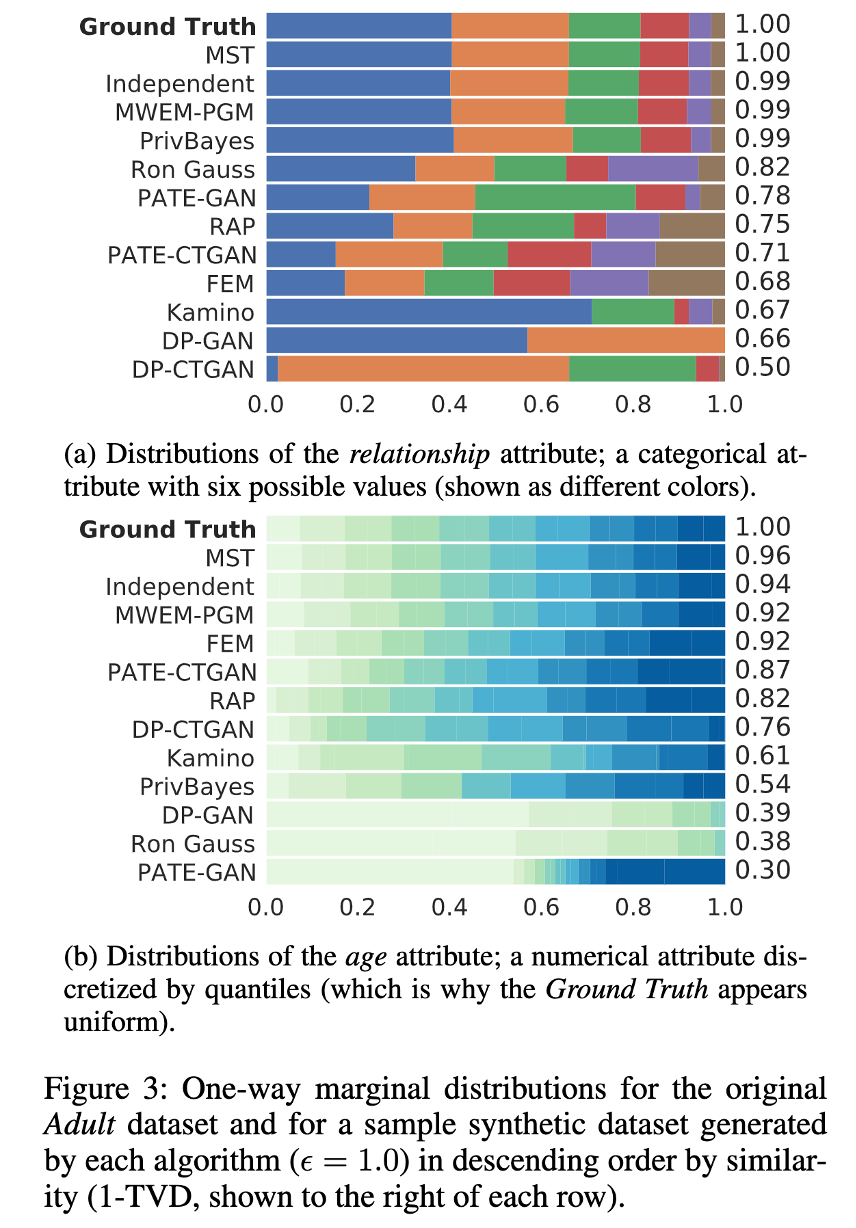
첫 행은 원본 데이터의 분포이고 나머지 행들을 알고리즘에 의해 생성된 합성 데이터의 분포이며, 실측과의 유사도가 높은 순에 따라 정렬했다. (1-TVD는 각 행의 오른쪽에 작성) 통상적으로 1-TVD가 0.75 미만이면 왜곡이 눈에 띄게 나타나는 것으로 확인되었다.
특히, FEM 의 경우 원래 데이터가 균일하지 않더라도 해당 알고리즘에서 생성한 데이터들은 매우 균일하게 나타나는 것을 확인할 수 있었다.
그리고 아래 그림 4에서는 원본 데이터(Ground Truth)로부터 생성된 합성 데이터에 대한 상관관계를 히트맵으로 보여주였다.

각 히트맵에서 셀은 속성 쌍에 해당하고 어두운 셀일 수록 상관 관계가 더 강한 것을 나타낸다.
결론
본 연구에서는 차분 프라이버시 합성 데이터 생성 알고리즘에 대한 체계적인 벤치마킹을 연구하였고, 각 알고리즘 별 유용성을 평가하였다.
결론적으로 Marginal 기반의 방법론들이 다른 방법론보다 성능이 우수한 것으로 나타났으며, GAN 기반의 방법론들은 표 데이터의 1차원적 통계치를 보존할 수 없는 것을 발견하였다.
'Security' 카테고리의 다른 글
| [Security] CIS (Center of Internet Security) Benmarks (0) | 2023.10.23 |
|---|---|
| [Security] 적대적 기계학습 (Adversarial Machine Learning) (0) | 2023.10.16 |
| [논문] APRIL: Finding the Achilles' Heel on Privacy for Vision Transformers (0) | 2022.12.21 |


